监控
概述
本节主要介绍的是Raibond监控体系中对Node机器监控,各服务组件监控及容器监控。监控服务由Rainbond组件rbd-monitor完成,在monitor组件中采用Sidecar设计模式思想整合Prometheus服务,并基于ETCD动态发现需要监控的targets,自动配置与管理Prometheus服务。monitor会定期到每个targets刮取指标数据,并将数据持久化在本地,提供灵活的PromQL查询与RESTful API查询。通过Granfana将监控数据可视化。在Rainbond资源管理后台与控制台中,基于monitor组件刮取的监控数据对应用与容器实现资源可视化等。monitor组件支持自定义报警规则,对接Alertmanager向用户发送报警信息。
当前rbd-monitor是冗余的工作模式,即对集群中所有节点的监控数据进行收集,当节点数量或监控数据量庞大时,对监控服务务必带来很大的压力。在后面的版本中我们会持续优化监控体系,支持多点部署、分布式数据采集、查询汇总等。
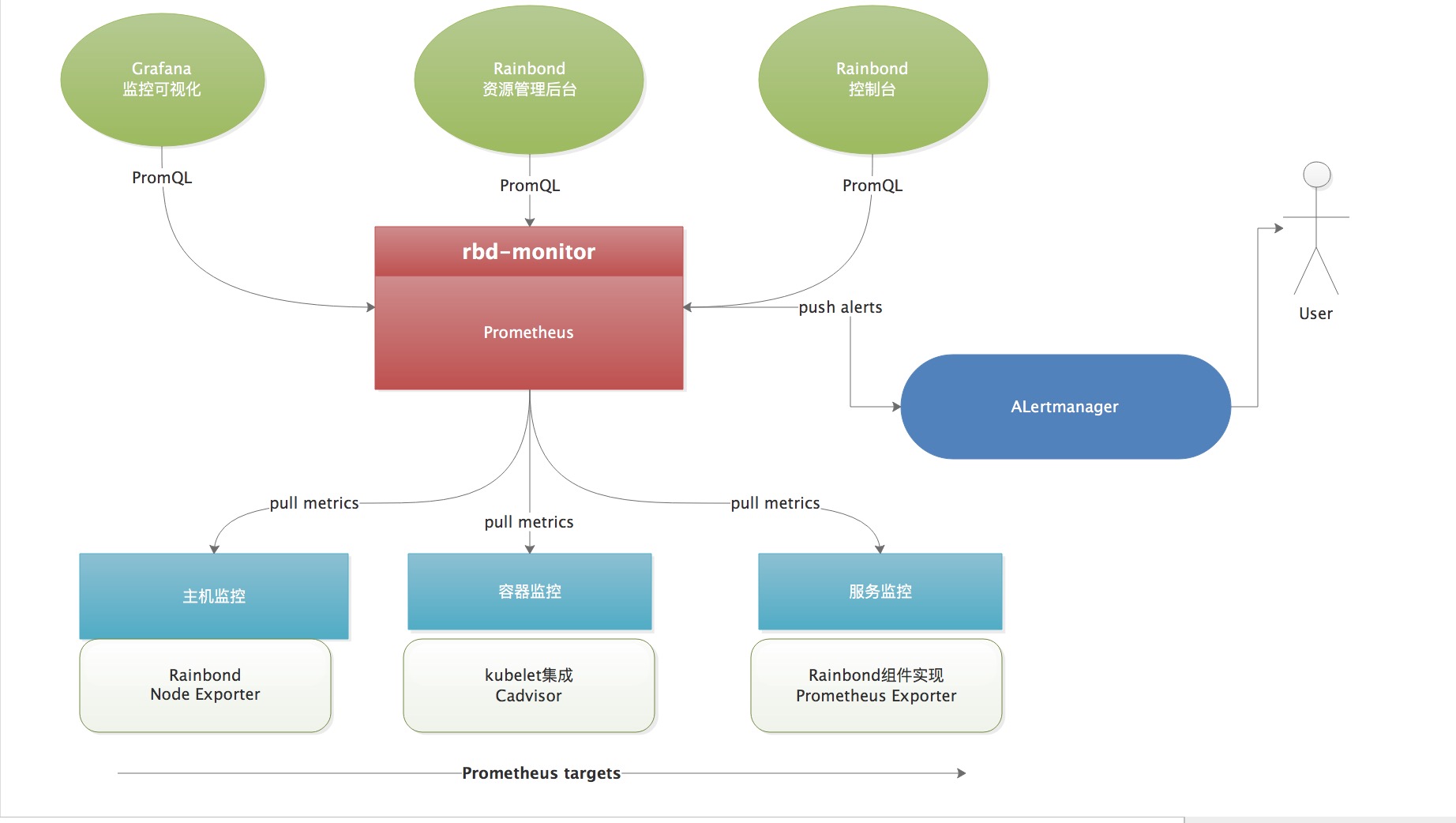
rbd-monitor提供Prometheus服务,在浏览器中访问管理节点的9999端口即可。Prometheus默认保存七天的数据,如果你需要更改配置,在/opt/rainbond/conf/master.yaml文件中的rbd-monitor配置中修改启动参数对应的值即可。
Node资源监控
有许多第三方组件提供导出现有的Prometheus指标供Prometheus拉取。Prometheus社区提供的NodeExporter项目可以对于主机的关键度量指标状态监控,Rainbond整合实现了NodeExporter并暴露在Node端口6100上,Prometheus可以通过http://node_ip:6100/metrics刮取本节点的主机监控指标及数据。
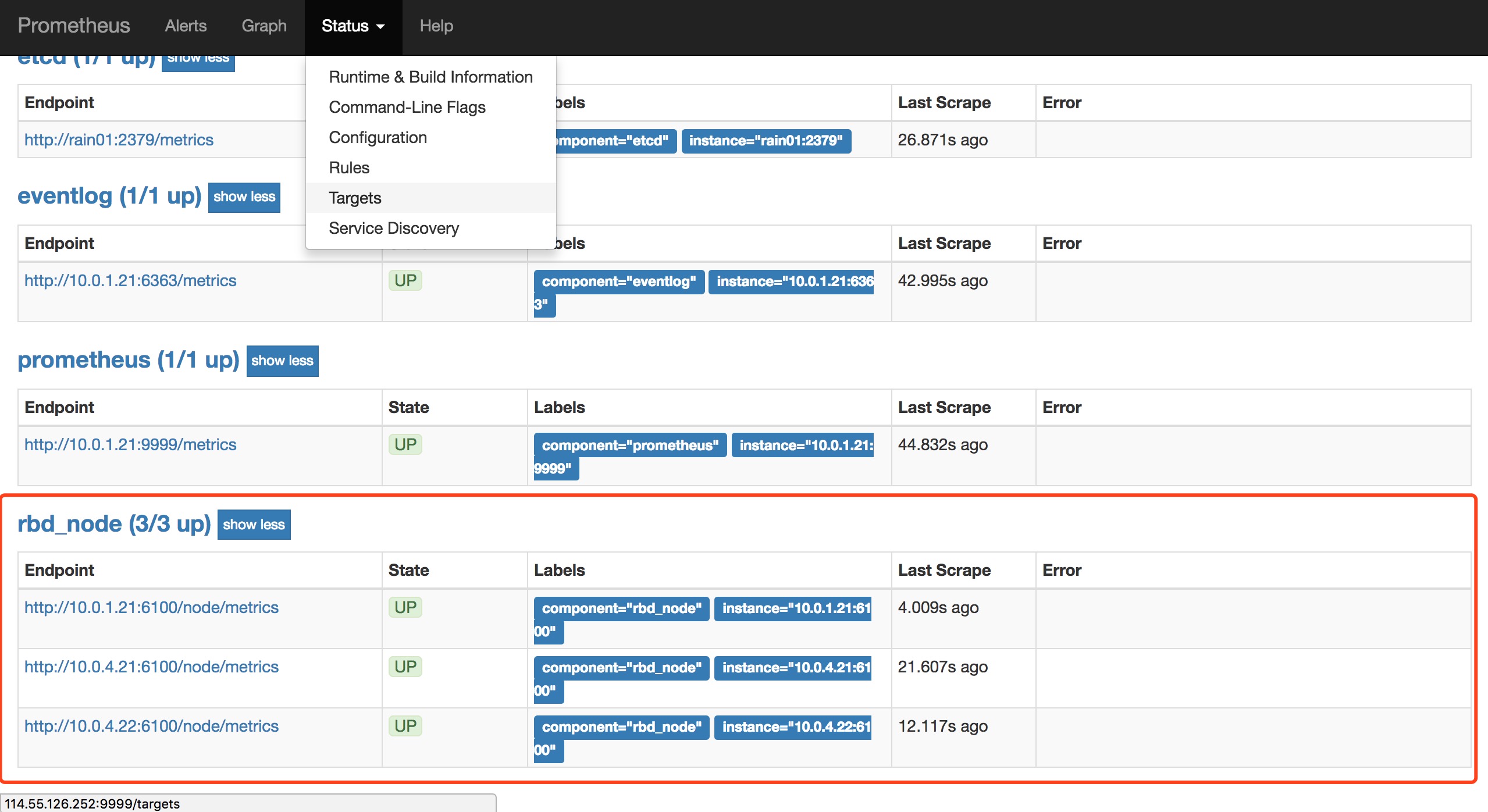
在Rainbond的monitor组件中,通过etcd中注册的node信息来发现各节点,将各节点主机监控的Metrics地址配置到Prometheus配置文件,Prometheus按配置的间隔时间定时到所有Node拉取指标数据,存储数据并可用PromQL提供丰富的查询。你可以使用Prometheus的查询语句查询各资源使用情况,或者配置Granfana模版更加直观展示主机的监控信息,在下面会详细介绍如何在Granfana配置Noed监控模版。
服务组件监控
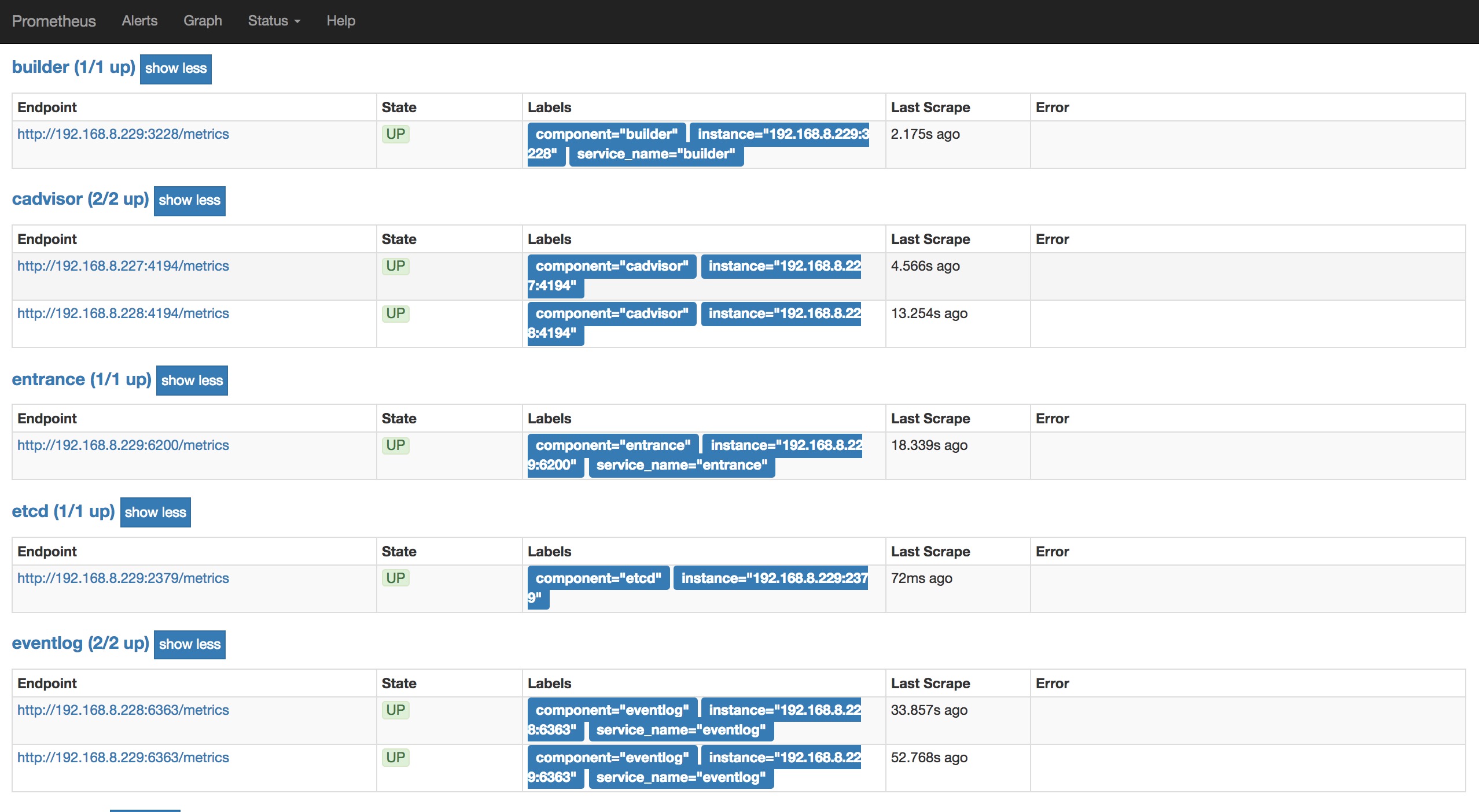
我们在Rainbond的各服务组件中自定义了Prometheus的Exporter,定义组件健康与工作等一些指标,并将指标与数据生成Prometheus可以识别的格式,通过metrics地址供Prometheus刮取。
在Prometheus的Targets中你可以看到这些服务组件,并可以查询这些服务组件暴露的指标及数据。
容器监控
Cadvisor是google开源的监控项目,Cadvisor对Node机器上的资源及容器进行实时监控和性能数据采集,包括CPU使用情况、内存使用情况、网络吞吐量及文件系统使用情况。
CAdvisor 启动通过调用 Linux 系统 inotify 监测 cgroup docker 目录的文件变化判断 docker 的创建和删除。找出Container对应的系统文件读取监控数据。
Kubernetes的生态中,cAdvisor是作为容器监控数据采集的Agent,cAdvisor集成在Kubelet中,其部署在每个计算节点上的kubelet启动时会自动启动cAdvisor,一个cAdvisor仅对一台Node机器进行监控,默认端口为4194,在URLhttp://node_ip:4194/metrics 提供监控指标及数据供Prometheus刮取,默认的刮取间隔为15s一次。
在Rainbond的monitor组件中通过etcd发现计算节点,将该节点CAdvisor提供的metrics地址配置Prometheus的配置文件,通过Prometheus指标丰富的label对容器及pod进行分类查找。并可实现对Rainbond应用的资源监控等。具体的监控项可在Granfana中配置模版,下面会详细说明如何在Granfana中配置容器监控模版。


应用异常事件监控
应用异常事件监控是捕捉并记录在RainBond中部署应用的OOM,运行异常情况等事件。便于发现并调整存在异常的应用,避免由于应用的持续异常影响资源及各服务的正常工作。
实现机制
Rainbond实现的worker组件中,对应用实例出的pod进行状态观察,当pod发生异常退出时触发事件来处理pod的退出信息,并将错误类型、错误原因、触发次数、最后出现时间等信息记录在数据库中供我们查询。
具体处理流程参考文档应用异常处理
使用Granfana 可视化监控
grafana是用于可视化大型测量数据的开源程序,他提供了强大和优雅的方式去创建、共享、浏览数据。dashboard中显示了你不同metric数据源中的数据。使用它可以快速搭建起主机及容器监控的可视化仪表盘,直观优雅的展示监控数据。通过每个仪表盘定义的Prometheus查询语句获取结果后渲染出可视化图形,还可以根据定义的标签对查询条件灵活的切换。
Grafana安装
当安装Rainbond时,默认不安装Grafana服务。如你想安装自己的Grafana,可参阅文档安装。
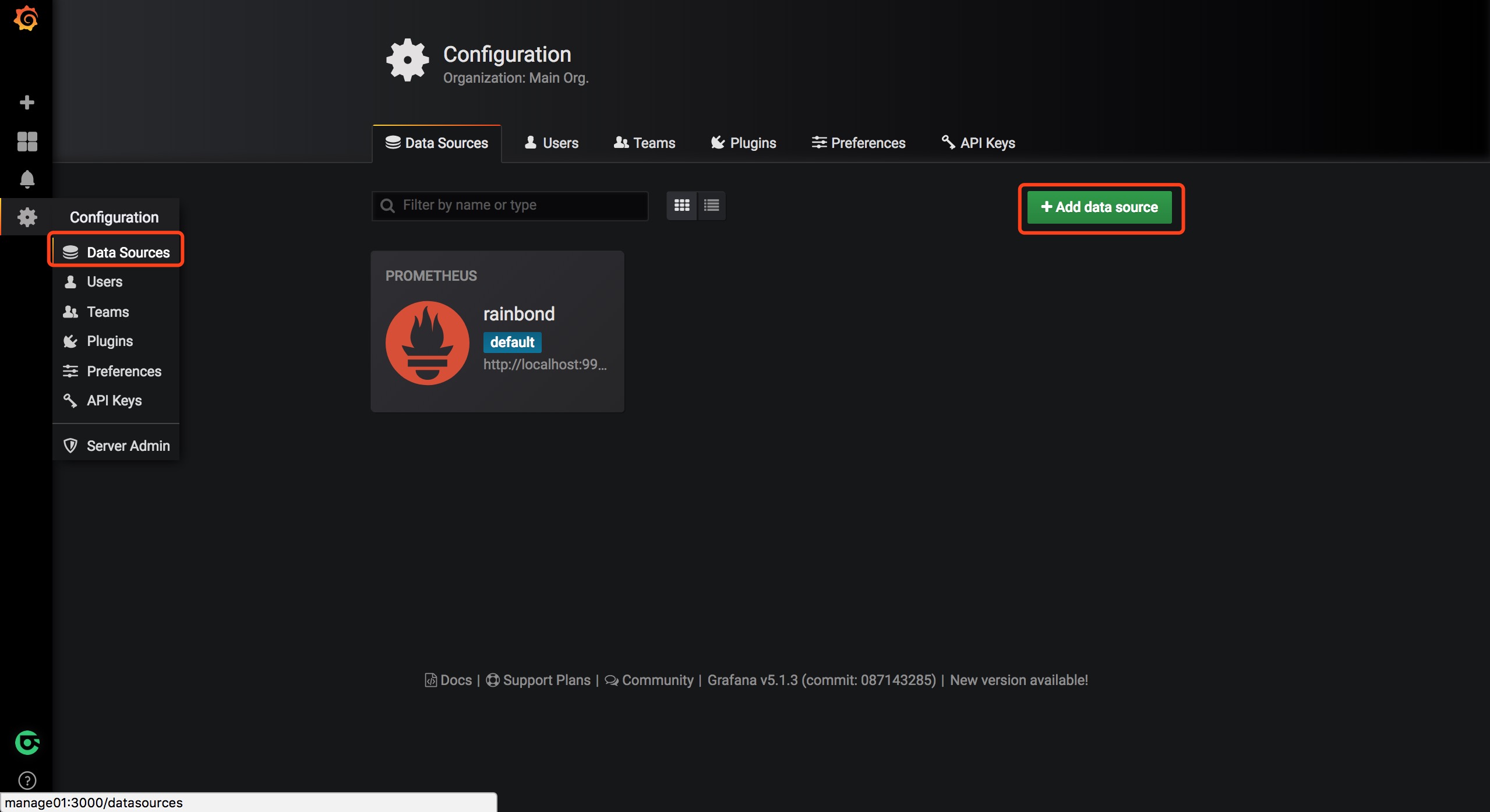
创建Prometheus数据源
- 单击Grafana徽标以打开侧边栏菜单。
- 单击侧栏中的设置图标,点击Data Sources。
- 单击“Add data source”。
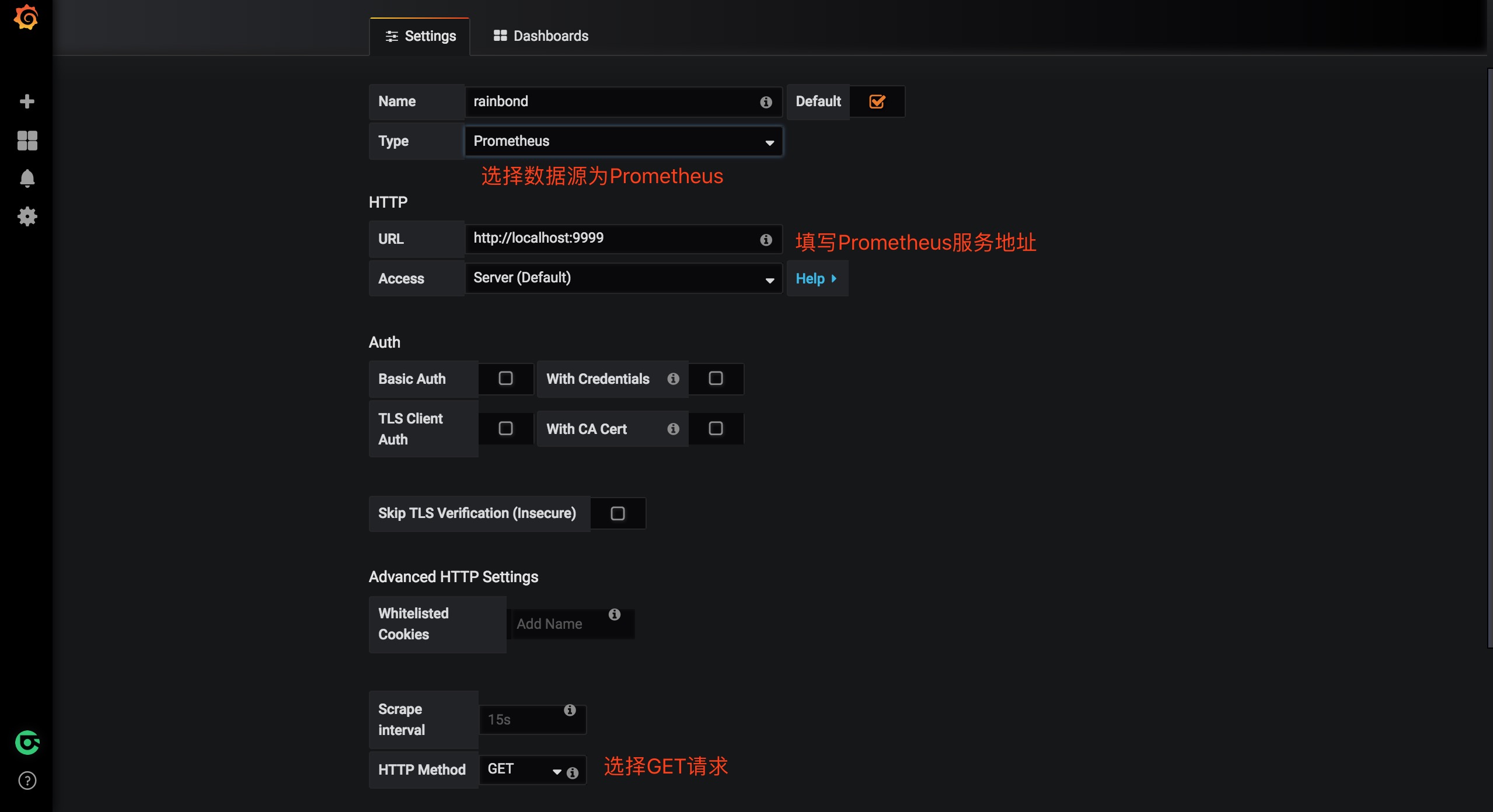
- 选择“Prometheus”作为类型。
- 设置适当的Prometheus服务器URL(例如,
http://localhost:9090/) - 根据需要调整其他数据源设置(例如,关闭代理访问)。
- 单击“添加”以保存新数据源。
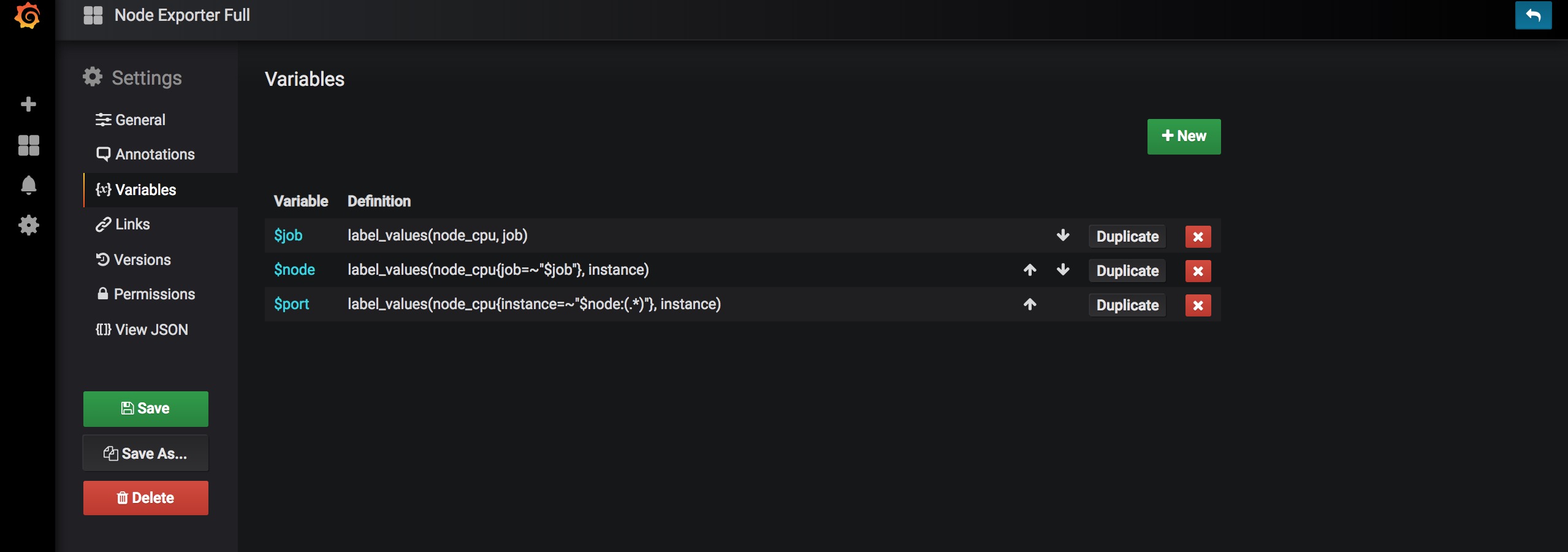
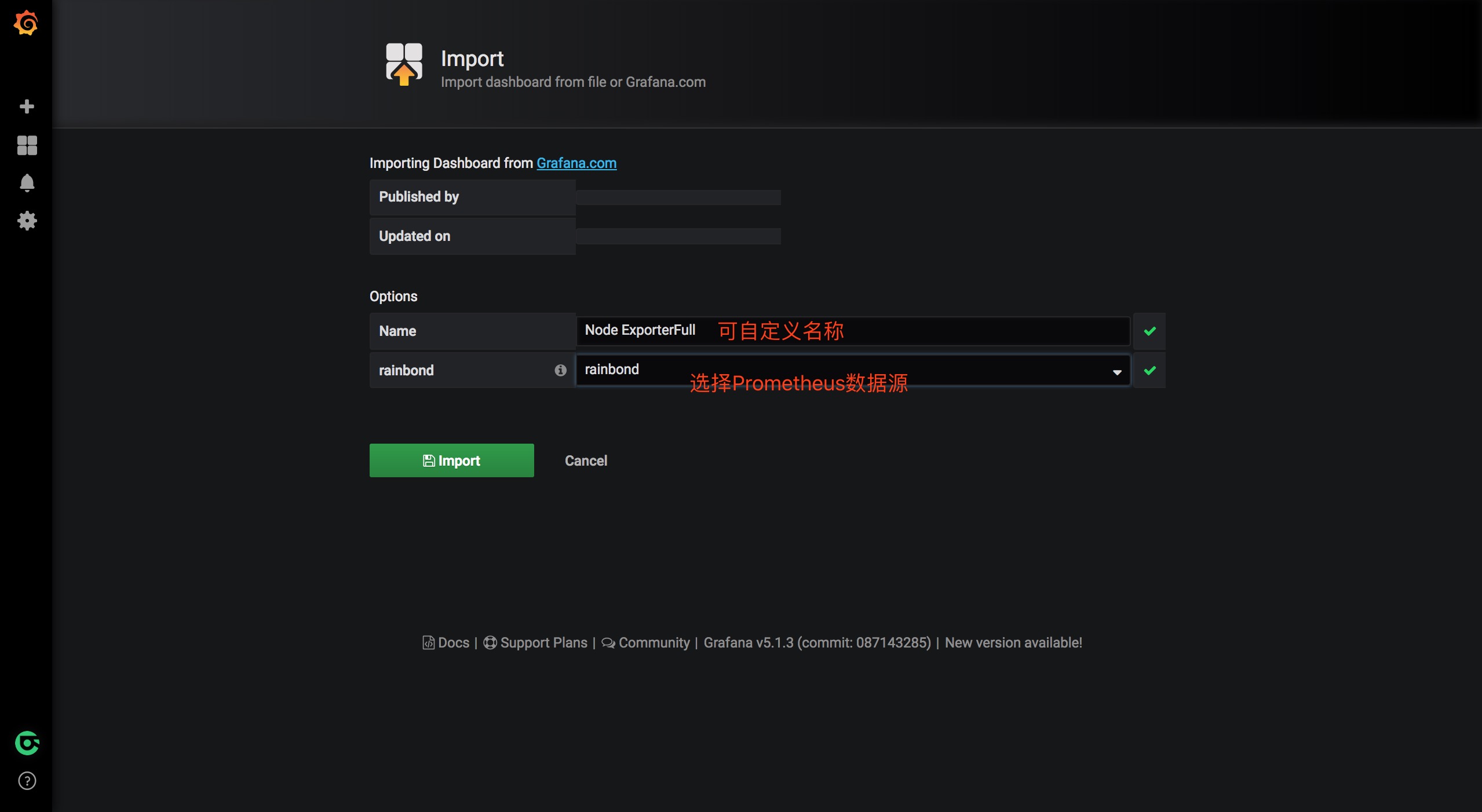
导入Node主机监控模版
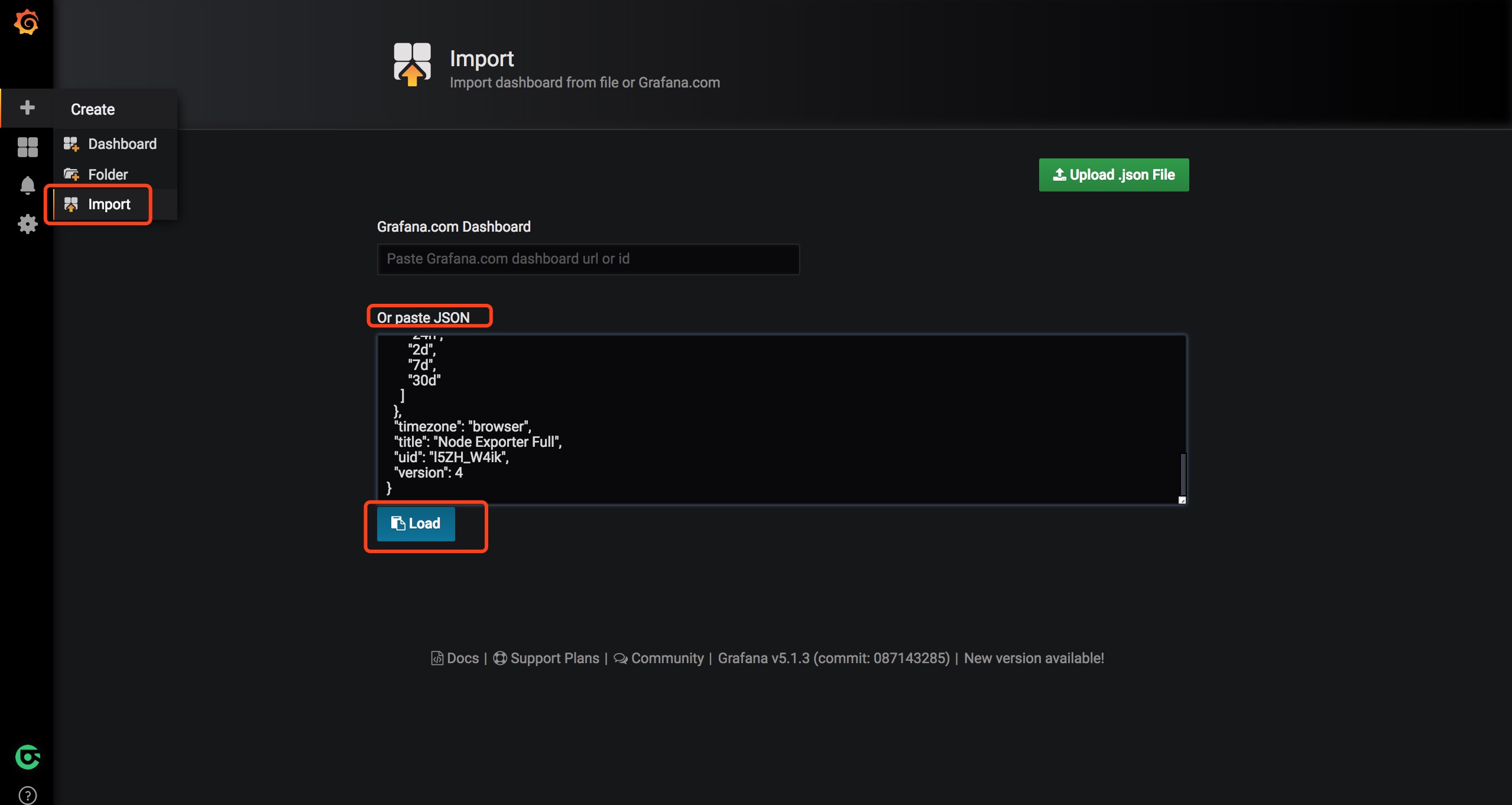
Grafana支持通过json文件快速导入你需要的仪表盘模版。点击这里获取Node Exporter的json文件,点击左侧菜单栏的加号,选择Import,将json数据复制粘贴到Or paste JSON一栏中,点击load按钮,输入名称,选择刚才添加的Prometheus数据源,点击Import即可添加模版或者输入我们提供的基础资源可视化Dashboard id(10014)
效果展示如下,可选择Host标签切换节点

导入容器监控模版
容器监控模版的导入方法与上面Node主机监控的导入方法一致,点击这里获取json文件。导入后可根据标签pod_name来查看某一个pod中容器的监控情况。Node标签可切换节点,interval可切换间隔时间。
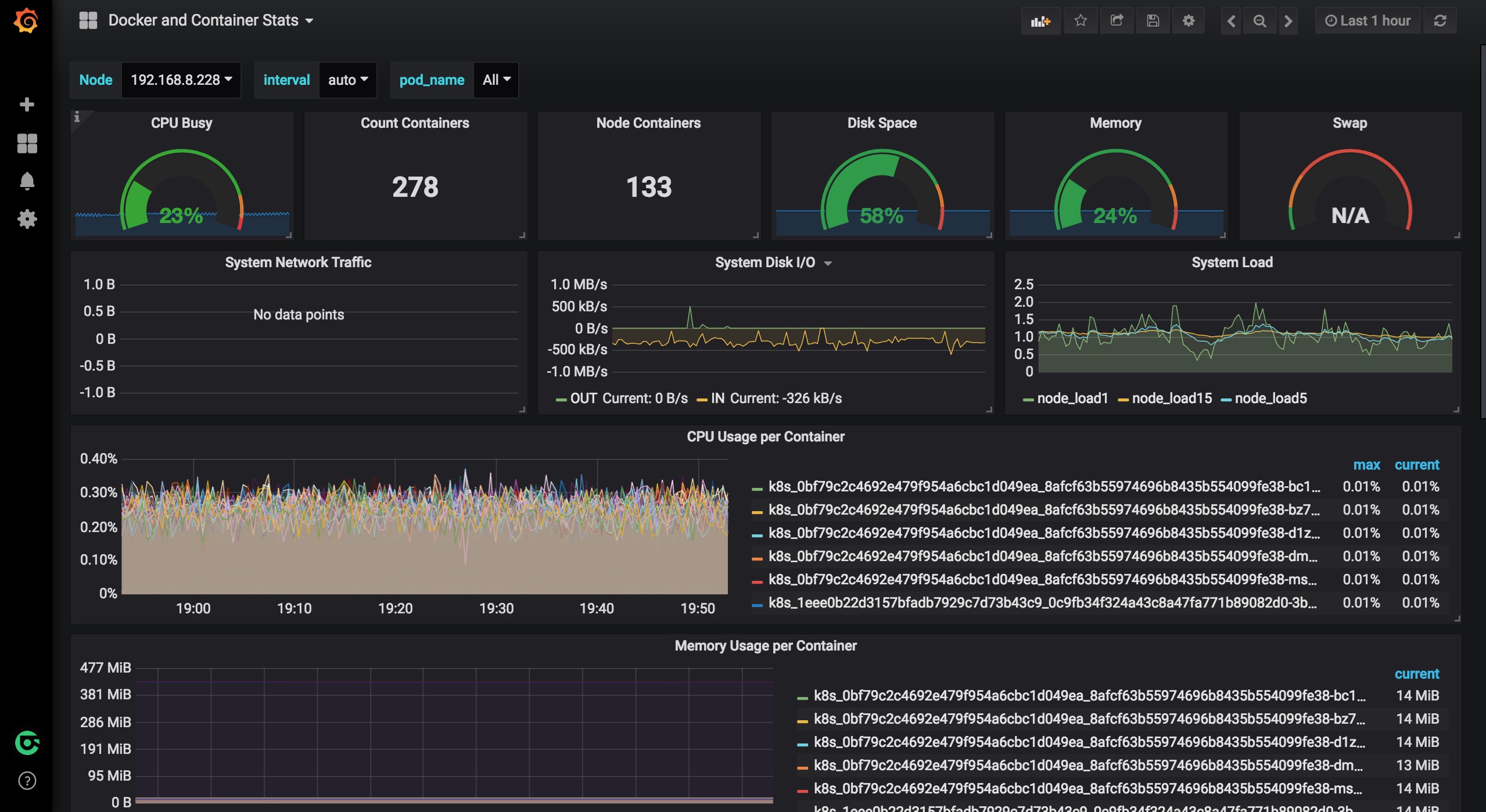
自定制
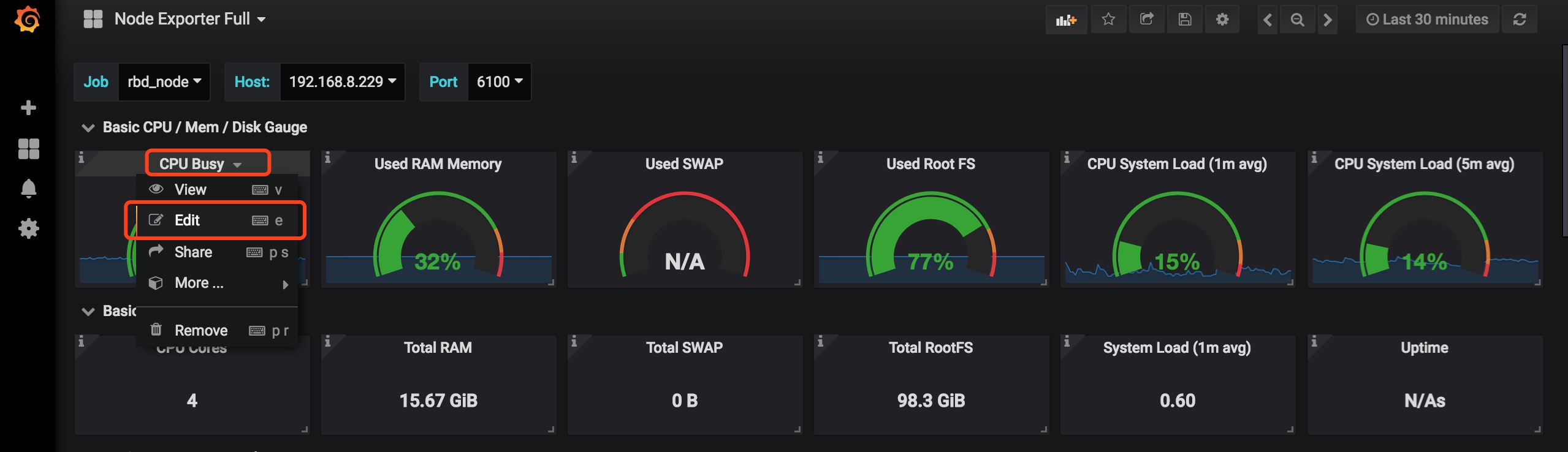
你可以点击每个仪表盘的名字,选择Edit进入编辑页面,在这里你可以看到该仪表盘对应的Prometheus查询语句,该语句查询的数据结果渲染出该仪表盘。你可以根据自己的需求修改这些参数及设置等。
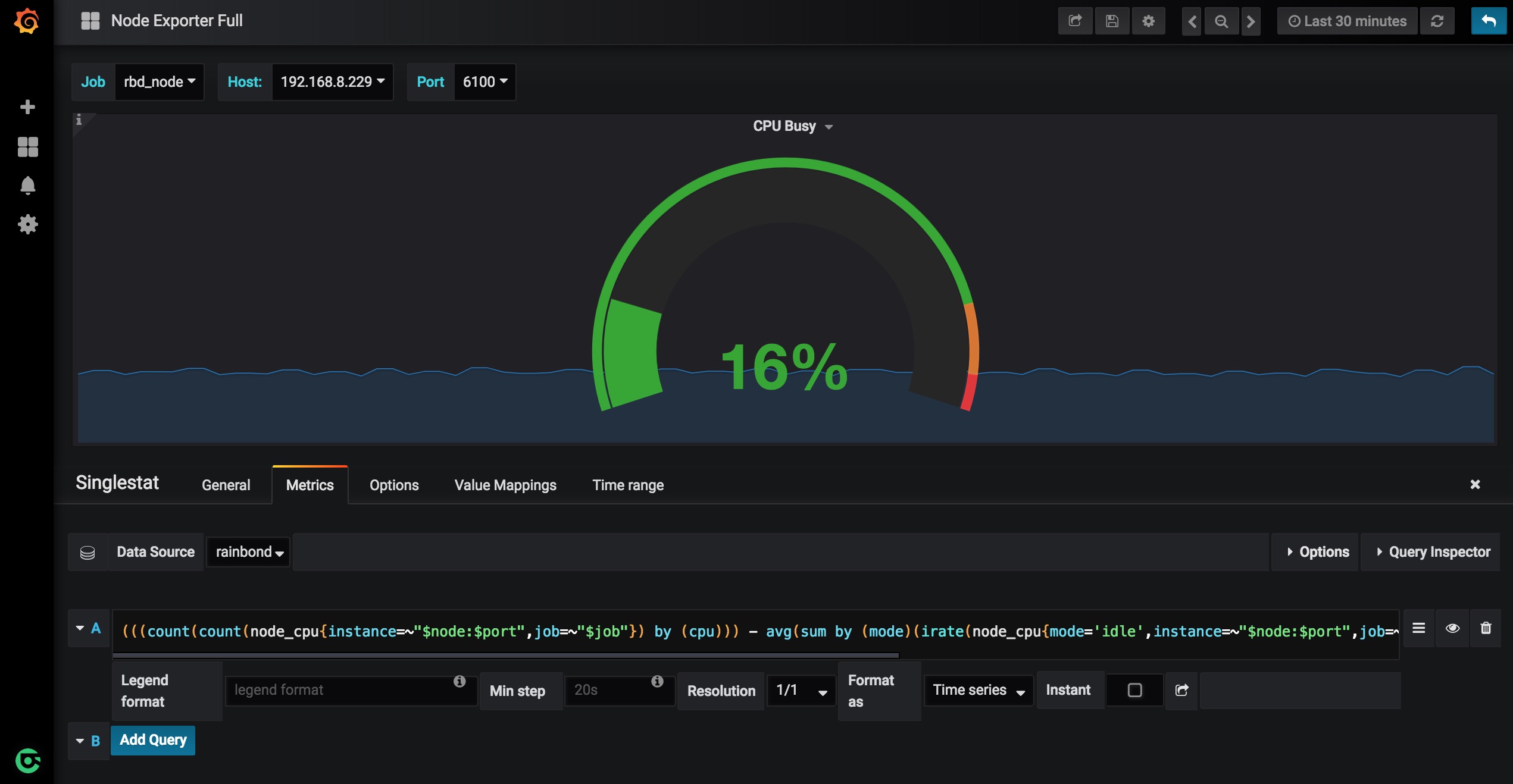
你也可以点击上方的设置按钮,来编辑整个模版的信息,添加Variables标签等。修改后记得点击Save保存更改哦。