使用 Statefulset 部署组件
对于kubernetes老玩家而言,StatefulSet这种资源类型并不陌生。对于很多有状态服务而言,都可以使用 StatefulSet 这种资源类型来部署。那么问题来了:挖掘机技术哪家强?额,不对。
如何在 Rainbond 使用 StatefulSet 资源类型来部署服务呢?
组件部署类型
通过在服务组件的其他设置中,更改 组件部署类型 即可选择使用 StatefulSet 资源类型部署服务,操作之前要注意以下几点:
- 组件需要处于关闭的状态;
- 对于有持久化存储的服务组件,切换组件部署类型会导致存储挂载的变更,一定要做好数据备份;
Rainbond 默认提供四种组件部署类型:
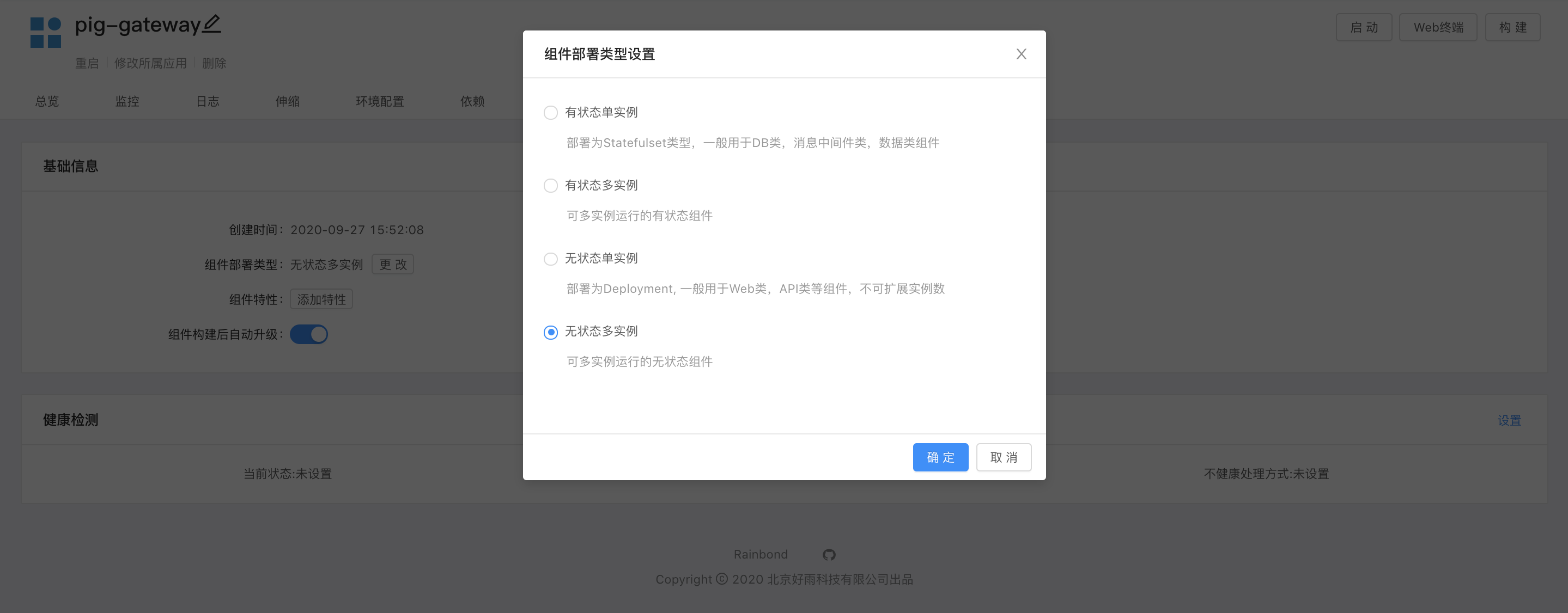
- 有状态单实例:使用 StatefulSet 部署服务,不可以进行实例的横向伸缩,实例数量始终为1;
- 有状态多实例:使用 StatefulSet 部署服务,实例数量可以进行横向伸缩;
- 无状态单实例:使用 Deployment 部署服务,不可以进行实例的横向伸缩,实例数量始终为1;
- 无状态多实例:使用 Deployment 部署服务,实例数量可以进行横向伸缩;
当你在 Rainbond 中将组件部署类型指定为有状态 (StatefulSet) 之后,服务组件将体现以下特性:
- 多实例状态下,所有实例将具备顺序性,实例的命名将类似于
gr6ec114-0gr6ec114-1,这一顺序性将体现为全生命周期的层面,顺序的启动、更新、重启、关闭。 - 上述的主机名在集群中将可以被解析,同团队下,尝试在任意 POD 中执行
nslookup gr6ec114-0。不同团队下,需要指定命名空间,可解析地址的完全地址为:gr6ec114-0.gr6ec114.3be96e95700a480c9b37c6ef5daf3566.svc.cluster.local其中3be96e95700a480c9b37c6ef5daf3566为命名空间。 - 多实例状态下,每个实例的持久化存储将被单独挂载,这意味着持久化数据在实例之间不再共享。
- 单实例状态下,执行更新操作时,实例将会在完全关闭之后,启动新的实例,这意味着服务会出现中断。
- 出于对持久化数据一致性的保护,运行了有状态服务的 k8s 节点一旦失去和管理节点的联络,处于
notready状态时,其有状态服务的实例不会自动迁移。
整体来看,利用 StatefulSet 资源类型来部署服务,带来了新的特性的同时,会显得呆板了一些,但接下来的探讨,会发现这些限制是有意义的。
细心如你一定会发现,我们将 StatefulSet 这种资源类型和 “有状态” 绑定在了一起。那么,一个新的问题冒了出来:什么是服务的 “状态”。
服务的“状态”
有状态(Stateful)服务 = 无状态(Stateless)的应用程序 + 有状态的数据
从有状态服务的名字就可以看出, 它和 StatefulSet 这种资源类型是有关联的。
单纯说概念,可能很难理解什么是有状态服务。让我来举几个例子:
- 最常见的有状态服务,就是DB类的数据库中间件。
对于常见数据库 Mysql 而言,同一份数据,在同一时刻只可以被一个 Mysql 程序使用。Mysql 在启动后,会在自己的数据目录下生成唯一的锁文件,并把这个文件“锁死”。这样一来,其他想要使用这份数据的 Mysql 程序,会因为发现这个锁文件被“锁死”,而中断启动的过程。这样做的好处,是保证了数据的强一致性,因为同一份数据在同一时刻,绝对只会被同一个 Mysql 应用程序所读写。
请回忆下 StatefulSet 资源类型带来的特性之一就是每个实例都会挂载独立的持久化存储,这样可以确保 Mysql 服务可以被扩展成多个实例运行起来,不会因为锁文件的原因被终止启动,但是因为彼此之间数据不共享,所以本质上实例之间没有什么关系。使用有状态单实例的方式运行 Mysql 看起来是最正确的选择。
情况类似的常见数据库中间件还有 Mongo、Postgresql、Redis、Etcd等。
- 另一种常见的有状态服务场景,是 Web 类的服务提供的粘性
Session。
这种粘性 Session 在某些情况下会保存在内存中,用来提供会话保持,本身也是一种数据。一旦将这种服务扩展多个实例,一旦访问到不正确的实例,那么就会因为找不到 Session 而丢失登陆态。在负载均衡中使用 IP Hash 算法进行流量的分发可以在某种程度上解决这个问题,来自同个 IP 的流量会被分发到指定的实例。但是我们更希望流量的分发是轮询的,这样可以确保每个实例的负载都是相近的,不会出现某个实例负载过高,而其他实例无所事事的情况。
这两种有状态服务场景,都向我们指出,对有状态服务而言,不同实例的数据是相互独立的。数据即“状态”。
相比较而言,无状态的服务就灵活很多。它们没有持久化数据,或者持久化数据支持共享。对于客户端而言,请求哪一个实例获得的返回都是一致的。这样的特性意味着可以随意扩展无状态服务的实例数量,灵活的应对流量。
使用云服务最大的好处之一,就是它提供的弹性和灵活性,在业务遭遇流量高峰时,可以快速扩展实例进行应对。从这个角度出发,我们希望服务都是 “无状态” 的。那么,一个新的问题冒了出来:我们可以去掉服务的 “状态”,使之变成无状态服务么?
处理服务的 “状态”
利用粘性 Session 保持登陆态的这类 Web 服务,其状态是可以被去掉的。
原理比较简单,把 Session 和 Web 应用程序剥离,存储到其他中间件中去即可,比如保存到Mysql、 Redis、Memcached等数据库中间件中去。市面上常见的 Web 框架都会支持这种功能,甚至把这种处理方式作为默认选项,因为这实在太棒了!
处理完的 Web 服务,就变成了无状态服务,可以任意扩展实例数量了。来自客户端的请求无论被分配到哪一个实例,其登陆态都到后端数据库中调取,返回正确的登陆态。在部署时,可以选择无状态多实例进行部署,即使用 Deployment 这种资源类型。
但是对于DB类的数据库中间件而言,其状态是不可以被随意去除的。
原因在于这类数据库中间件使用自己的机制来确保数据强一致性,就比如 Mysql 的锁文件机制,指定的实例只能去读写对应自己的那一份数据。对这一类有状态服务而言,每个实例独享一份持久化数据可以算作是必须的条件。并且随意扩展实例数量,会遭遇很多致命的问题:比如数据不一致,或者程序运行失败等等。这一类的有状态服务只能单点部署吗?
这些数据库中间件的出品厂商或者社区,也都很关注如何实现高可用方案,来解决上述的问题。甚至近些年推出的数据库中间件,在设计阶段就会被设计成分布式架构。比如 Etcd 对自己的定义就是:可靠的强一致性分布式键值数据库。其内部使用 Raft 协议进行实例间选举来明确统一的leader。而对于 Mysql 这样比较老牌的数据库中间件,也具备基于 Binlog 复制实现的主从集群方案。
所以针对这一类无法去除状态的服务而言,我们的思路与宗旨,就是遵循其自身支持的集群方案,来实现高可用以及实例数量扩展。
实际部署这些集群方案时,可以总结出,大多数集群方案需要满足以下条件:
- 每个实例挂载单独的持久化数据;
- 实例间需要获取彼此的通信地址,来进行选举或者数据同步等动作,比如可解析的主机名或域名。获取地址时一定要使用主机名或域名而非实例 IP,因为随着实例的重启,主机名或域名不会改变,但是IP可能会改变,这很重要;
- 实例数量是有要求的,一般情况下选择 3、5、7··· 等奇数,来保证集群不会出现脑裂;
回想一下 StatefulSet 资源类型的特性,它可以满足上述的所有条件,就是为了有状态服务而生的。所以这一类有状态服务,其组件部署类型无论如何要使用有状态单/多实例。